Podría poner aquí la historia de los compiladores y como se desarrollaron pero eso cualquiera lo puede conseguir en San Wikipedia por lo que yo tocaré otros puntos que me parecen interesantes.
Conceptos básicos
Como primer punto, sería bueno saber que es un traductor: programa que toma como entrada un escrito en un lenguaje llamado fuente y devuelve el equivalente en otro lenguaje llamado lenguaje objeto. Con esto en mente ahora podemos definir un compilador.
- Compilador: Es un traductor que recibe como fuente un lenguaje de alto nivel y devuelve un lenguaje objeto de bajo nivel. (También en wikipedia).
Ahora bien, sin pasar por mucha teoría diré que en 1959, Rabin y Scott proponen el empleo de AFD y AFN para el reconocimiento lexicográfico de los lenguajes. Aquí es cuando preguntan ¿Qué son AFD y AFN?¿A qué te refieres con lexicográfico? Bien, si no terminaron de leer todo lo que dice Wikipedia yo se los explico rápido.
Para la pregunta sobre lexicográfico les diré que el proceso de "compilación" se divide en dos principales etapas: análisis y síntesis. Y algo destacado aquí es que éstas se unen mediante un código intermedio que produce toda la magia en lo que conocemos como lenguajes multiplataforma. Que comience la breve explicación.
Análisis, Síntesis y Código Intermedio
Sólo imaginen una computadora con Windows y otra con Ubuntu, escribimos nuestro típico "Hola mundo" en el lenguaje C ¿Por qué funciona el mismo código en Windows y Linux? Adivinaste: Código intermedio.
El análisis es aquella etapa que se realiza con el código de alto nivel. Esta define cómo interpretar el código fuente dado. Podríamos decir que un Hola Mundo en Scala y uno en C aplican el análisis y generan un código intermedio igual (quiero decir, similar). Por esto, nuestros programas en C (sin contar librerías) son lo mismo en cualquier equipo y sistema.
Ahora, la síntesis es la que toma un código intermedio y 'revisa con qué CPU cuenta la computadora, que sistema operativo es y generar el código objeto' (dicho coloquialmente). Esto es lo que hace que nuestro programa en C pueda ejecutarse en Windows o en Mac OS X. Cada sistema recibirá el mismo código intermedio pero tendrá diferente código objeto.
Además, en estas dos etapas podemos encontrar varias sub-etapas. Por decir algunas, dentro de la síntesis está la optimización del código y la generación del código objeto. Algunas sub-etapas del análisis son: análisis léxico, sintáctico y semántico.
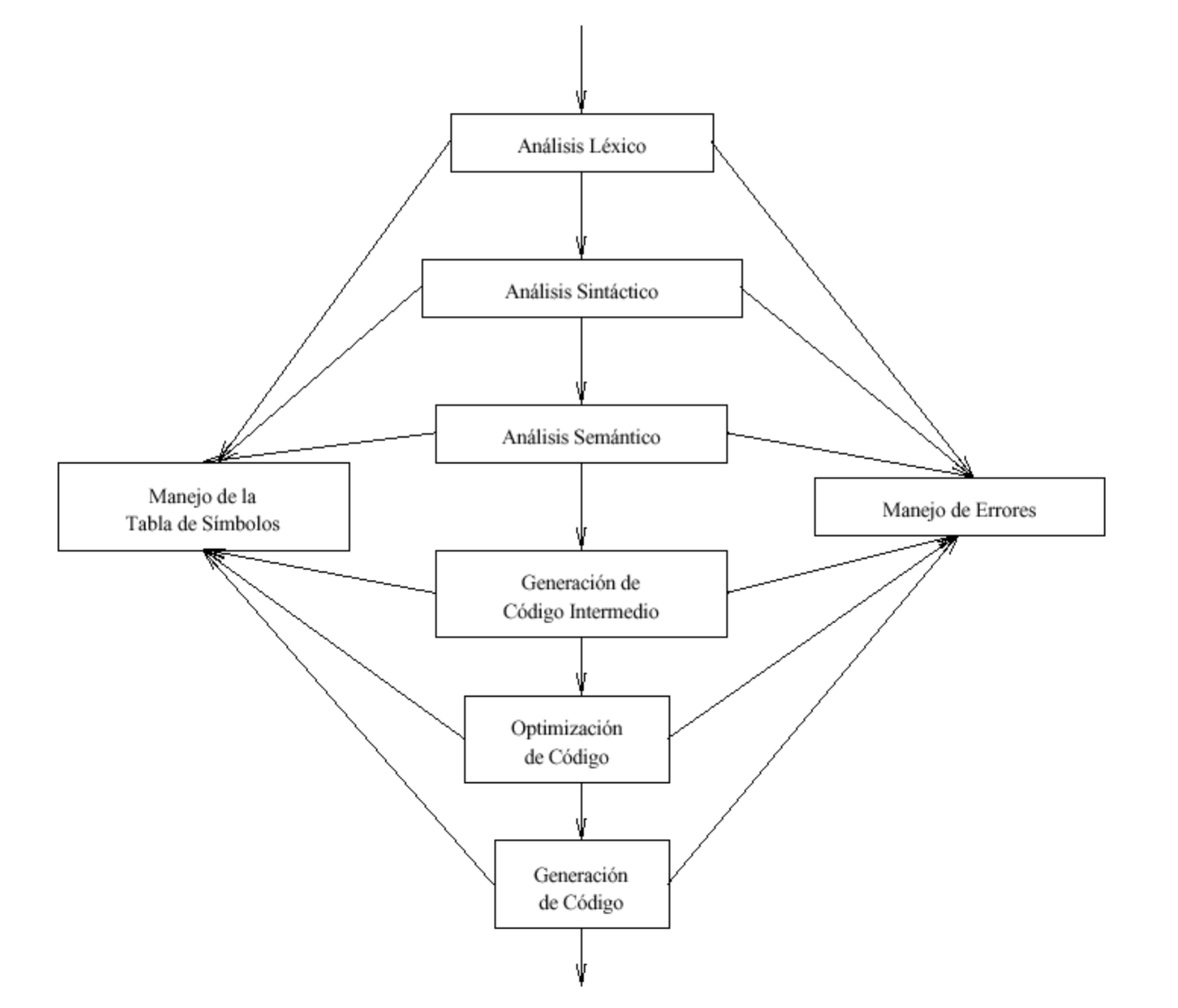 Imagen 1.- Algunas sub-etapas de un compilador.
Imagen 1.- Algunas sub-etapas de un compilador.
El análisis léxico o lexicográfico se encarga de leer caracter por caracter desde la entrada y va formando grupos de caracteres que tienen relación entre sí llamados tokens que son de utilidad para la siguiente etapa del compilador, análisis sintáctico.
El análisis léxico suele ser realizado mediante el uso de AFD y AFN; lo que propusieron Rabin y Scott en 1959.
Autómatas Finitos
Un AFD es Autómata Finito Determinista y AFN es Autómata Finito No determinista. Todo empieza a tener sentido ¿no? Entonces pasemos a definir primero qué es un Autómata.
Seré breve. Un autómata es un modelo matemático abstraído de un sistema de transición de estado finito. A ver, y ¿Qué es esto? Definamos algunos conceptos conceptos.
- Estado de un sistema: Descripción instantánea del mismo sistema, "fotografía" de la realidad en un momento preciso.
- Transiciones: Cambios de estado, ya sea espontáneos o en respuesta a entradas externas.
- Sistema de transición de estado finito: Un sistema que consiste de un número finito de estados y transiciones en.
Para quienes conozcan sobre temas de Sistemas digitales, es similar a máquinas de mealy y moore.
Podríamos decir que un autómata parte de un estado inicial y según ciertos valores de entrada va cambiando de estado, hasta llegar a un estado final. Para el caso en que se terminen los valores de entrada y no esté en un estado final, diremos que el conjunto de valores dados no es aceptado por el autómata.
Dado que se recibirá un código fuente como entrada, los valores de transición le llamaremos alfabeto y el conjunto de valores de entrada será una cadena (una línea del código fuente)
Usualmente en los diagramas de un autómata finito, el estado inicial se representa una pequeña flecha apuntándole y los estados finales un doble círculo. Como el alfabeto suele estar compuesto de letras, en los estados se usan números, sólo por convención. Veamos una imagen.
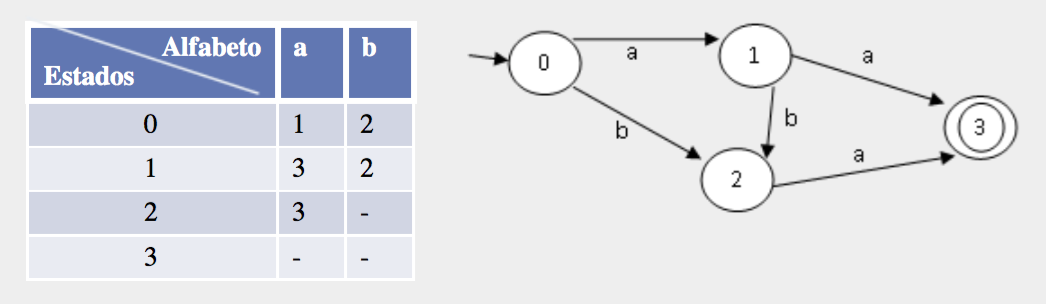 Imagen 2.- Tabla de Transición (derecha) y Diagrama de Transición (izquierda) de un autómata finito.
Imagen 2.- Tabla de Transición (derecha) y Diagrama de Transición (izquierda) de un autómata finito.
Como se puede apreciar en la imagen anterior, los autómatas finitos se pueden representar mediante diagramas y tablas de transición. Imaginemos lo siguiente y síganlo ya sea en la tabla o en el diagrama: Comenzamos partiendo del estado '0' y recibimos una 'a'. Ahora estamos en el estado '1'; recibimos otra 'a' y cambiamos al estado '3' donde:
- Si ya no recibimos nada más, entonces podemos decir que la cadena 'aa' es aceptada en el lenguaje del autómata.
- Si solo hubiéramos recibido una 'a' (si el autómata se quedaba en un estado no final). Entonces la cadena 'a' no es aceptada por el autómata.
- Si en el estado 3, que no tiene transición a ningún otro estado se hubiera dado en la entrada algo más entonces 'aaX' es un lenguaje no válido.
- Si se recibe algo que no está dentro del alfabeto también decimos que es una entrada no válida.
Dado que es un autómata muy simple podemos decir que el lenguaje aceptado es: 'aa', 'aba', 'ba'. Intenta recorrer el diagrama o la tabla con estas cadenas de entrada, deberías de terminar en el estado 3 en todas. Y si intentamos con algo como 'ab', 'aaa', 'aaba', 'baa', 'b' se detiene en un estado no final o busca una transición en el estado 3 que no existe, en ambos casos se maneja como error y decimos que es un lenguaje no aceptado por el autómata.
Determinista y No Determinista
Entonces como les decía... -Espera Jordy! aún no has definido la diferencia entre autómata Determinista y No determinista- Eso es lo que estoy por hacer.
Con mis propias palabras: Un autómata es Determinista cuando cada estado tiene ninguna o una sola transición a un determinado elemento del alfabeto. Dicho de otra manera, es cuando el estado X tiene una única transición con el elemento A del alfabeto. La imagen anterior es un ejemplo de un autómata determinista. Para el caso en el que esto no se cumpla entonces decimos que el autómata es no determinista.
La siguiente imagen muestra un autómata no determinista. Observa que el estado q0 puede ir a los estados q0,q1 y q2 con el mismo caracter de entrada 'a'.
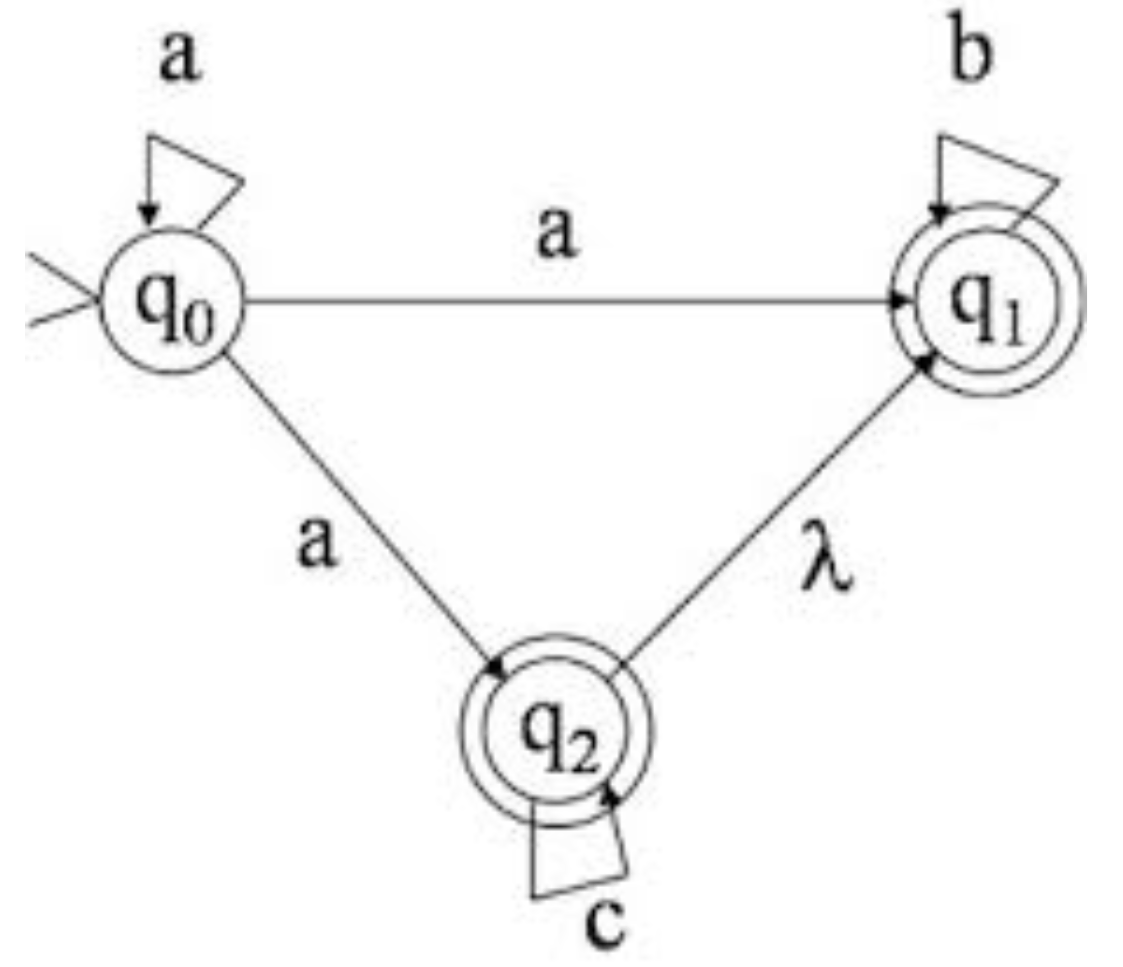 Imagen 3.- Autómata finito no determinista.
Imagen 3.- Autómata finito no determinista.
Implementación en Python de un AFD
Si quisiéramos implementar un AFD en python deberíamos de tener en consideración:
- Cómo introducir los datos del autómata a nuestro algoritmo indicando el alfabeto, estado inicial, estados finales y otros estados.
- Cómo validar una cadena y cuándo esta es válida o no para nuestro autómata.
- Y las subtareas que las tareas anteriores piden.
Propuesta:
Aprovechando la sintaxis que tienen las tablas de transición de los autómatas, podemos definir 'tablas' en archivos de texto plano (Como en la Imagen 2). Si nos damos cuenta, en el primer renglón de la tabla se encuentran los elementos del alfabeto. Después, por cada renglón que vayamos leyendo, el primer elemento será el estado actual y los demás son las transiciones. Hay que tener en cuenta que se debe de definir un modo para reconocer si es estado inicial o final.Entonces debemos de abrir un fichero con la tabla y leer ordenadamente.
Fichero:
a b
i 0 1 2
1 3 2
2 3 -
f 3 - -Este sería nuestro fichero para un autómata como el de la Imagen 2. La 'i' y la 'f' nos servirán para hacer saber al algoritmo cual es el estado inicial y cuales son los finales.
Seleccionar archivo del autómata:
def pick_file():
'''
(None) -> StringPath
Función que abre un diálogo para seleccionar un archivo y devuelve el
path del archivo
NOTA: Si el usuario pulsa "Cancelar", el valor devuelto será cadena vacía ("")
'''
from Tkinter import Tk
from tkFileDialog import askopenfilename
Tk().withdraw() # No queremos una GUI completa, así que se oculta el resto de la GUI
filename = askopenfilename() # Mostramos un Diálogo para abrir ficheros
return filename # Se regresa el pathLeer archivo del autómata y crear el AFD:
def open_AFD(path):
'''
(StringPath) -> AFD
'''
# Abrimos el fichero que contiene el AFD
fich = open(path, 'r') # Ruta del fichero, solo lectura
# Empezamos leyendo el alfabeto
alfabeto = fich.readline().split()
# Definimos los estados
estados = []
edoini = []
edosfin = []
transiciones = []
# Leemos todos los estados
linea = fich.readline()
while linea:
linea = linea.replace("\n", "")
tokens = linea.split()
# Si nos indica que es el estado inicial
if (tokens[0] == 'i'):
if (len(edoini) > 1):
sys.exit("\nERROR: Se encontró más de un estado inicial.\n")
edoini.append(tokens[1])
estados.append(tokens[1])
tokens = tokens[2:]
# Si nos indica que es un estado final
elif (tokens[0] == 'f'):
edosfin.append(tokens[1])
estados.append(tokens[1])
tokens = tokens[2:]
# Los que no entran en los casos anteriores
else:
estados.append(tokens[0])
tokens = tokens[1:]
transiciones.append(tokens)
# Actualizamos
linea = fich.readline()
print "El archivo se ha cargado correctamente"
# Podríamos considerar una buena idea implementar una tablahash de tablashash
# El modo de acceso sería:
# transhash[edoactual][elemento_entrante]
# Lo comentado anteriormente se verá con más detalle después
# Comenzamos a crear nuestro AFD (transhash)
i = 0
j = 0
transhash = {}
for edo in estados:
transhash[edo] = {} # Para cada estado en las transiciones, añadimos su dict/hash asociado a la letra
for letra in alfabeto:
transhash[edo][letra] = transiciones[i][j]
j += 1
i += 1
j = 0
print "Se ha creado la tabla de transiciones con exito"
print "El alfabeto válido es el siguiente:"
print alfabeto, "\n"
return alfabeto, edoini[0], edosfin, transhashPerfecto! ahora que ya tenemos nuestro autómata en una estructura de datos lo único que hace falta es que el programa tome una cadena y ocupar nuestra estructura para verificar si la cadena es válida o no, tomando en consideración los puntos ya mencionados antes.
Para validar la cadena yo definí lo siguiente:
def validar_cadena(cadena):
'''
(str) -> bool
Se valida si la cadena proporcionada es una palabra válida para el autómata
'''
alfabeto, edoini, edosfin, transhash = open_AFD(pick_file())
edoactual = edoini
char = cadena[0]
n = len(cadena)
i = 0
while (i != n):
if (not (char in alfabeto)):
return False # Se dió una cadena que no está dentro del alfabeto válido
if (transhash[edoactual][char] == '-'):
return False # Se encontró que no es válido y no pertenece al lenguaje aceptado por el autómata
edoactual = transhash[edoactual][char]
i += 1
if (len(cadena) == i):
break
char = cadena[i]
if edoactual in edosfin:
return True # Terminó bien el recorrido y en un estado final
return False # Terminó en un estado NO FINALEjecución
if __name__ == '__main__':
if validar_cadena(raw_input("\nIntroduce la cadena a validar\n>>> ")):
print "La cadena es válida :D"
else:
print "La cadena NO ES VALIDA"Pues como en una receta de cereal con leche: ponemos todo junto y comemos. Del mismo modo juntamos estas funciones sin olvidar el siempre útil If-Main de Python. Pasemos a ver los resultados de la ejecución usando las mismas cadenas de entrada que dijimos antes que eran válidas para nuestro autómata:
Introduce la cadena a validar
>>> aa
El archivo se ha cargado correctamente
Se ha creado la tabla de transiciones con exito
El alfabeto válido es el siguiente:
['a', 'b']
La cadena es válida :D
Introduce la cadena a validar
>>> aba
El archivo se ha cargado correctamente
Se ha creado la tabla de transiciones con exito
El alfabeto válido es el siguiente:
['a', 'b']
La cadena es válida :D
Introduce la cadena a validar
>>> ba
El archivo se ha cargado correctamente
Se ha creado la tabla de transiciones con exito
El alfabeto válido es el siguiente:
['a', 'b']
La cadena es válida :D
Introduce la cadena a validar
>>> aaba
El archivo se ha cargado correctamente
Se ha creado la tabla de transiciones con exito
El alfabeto válido es el siguiente:
['a', 'b']
La cadena NO ES VALIDA
De la misma forma, si metemos alguna cadena no válida, como se muestra en la última ejecución, nos muestra un mensaje diciendo que la cadena no es válida.
Espero esta publicación les haya ayudado a comprender un poco más sobre las bases de los compiladores.
Dudas / Comentarios
Si tienes alguna duda o comentario, escríbelo aquí o mandame un tweet a @JordyCRPetrucci y te ayudaré con gusto.