Ejemplo 1: Ejemplo básico con dataset de diabetes propio de scikit-learn
Este ejemplo es sencillo ya que no necesitamos más que scikit-learn únicamente para observar cómo funciona el algoritmo
# -*- coding: utf-8 -*-
# Imports
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
# Cargamos el dataset que ya trae scikit-learn
diabetes = datasets.load_diabetes()
# Usamos solo una característica del dataset
X = diabetes.data[:, np.newaxis, 2]
# Separamos la información en training y test
X_train = X[:-20]
X_test = X[-20:]
# Separamos la salida (output) en training y test
y_train = diabetes.target[:-20]
y_test = diabetes.target[-20:]
# Creamos el objeto de linear regression
regr = linear_model.LinearRegression()
# Ahora entrenamos el modelo usando los conjuntos de training
regr.fit(X_train, y_train)
# Coeficientes
print 'Coefficients:', regr.coef_, regr.intercept_
# RSS
print "Residual sum of squares: %.2f" % np.mean((regr.predict(X_test) - y_test) ** 2)
# Ploteamos las salidas
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, regr.predict(X_test), color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
Salidas
Coefficients: [ 938.23786125]
Residual sum of squares: 2548.07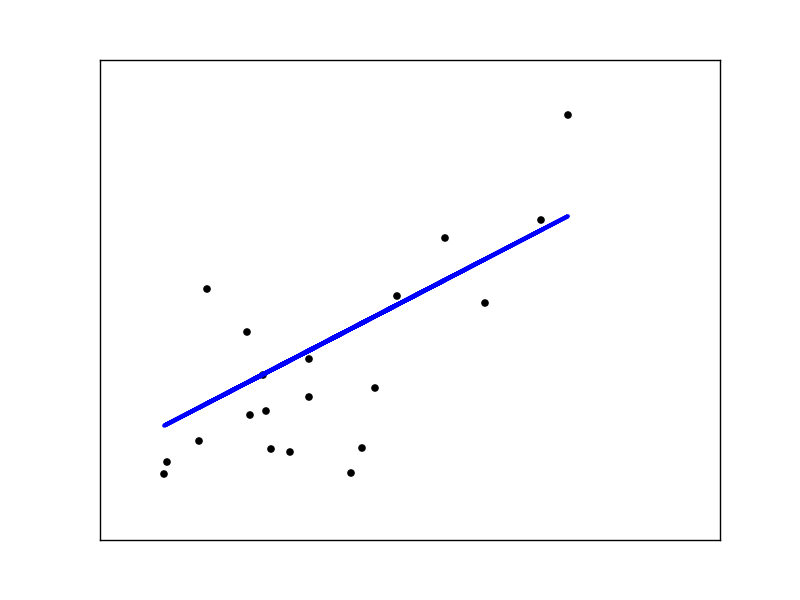 Plot 1: Dataset de diabetes y su modelo predictivo.
Plot 1: Dataset de diabetes y su modelo predictivo.
Yo no soy el autor del código anterior! lo puedes encontrar en la página de scikit-learn en sus ejemplos (aquí), sin embargo, aquí explico y detallo un poco poniendo comentarios con intención de ayudar a los que se les dificulta el inglés (no se debería de dificultar a los programadores pues la gran mayoría está en inglés).
Ejemplo 2: Cargando un dataset de diabetes en formato CSV a NumPy
# -*- coding: utf-8 -*-
import numpy as np
import urllib
from sklearn import linear_model
import matplotlib.pyplot as plt
# URL de nuestro dataset
# En 'http://archive.ics.uci.edu/ml/' podemos encontrar varios
url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
# Descargamos el archivo CSV de internet
raw_data = urllib.urlopen(url)
# Cargamos el archivo como una matriz de numpy
dataset = np.loadtxt(raw_data, delimiter=",")
# Separamos las columnas del data set que no interesan
# NOTA: las columnas se empiezan a numerar desde 0
# Segunda Columna: Concentración de glucosa
# Sexta Columna: Indice de masa corporal
X = dataset[:, np.newaxis, 1]
y = dataset[:, np.newaxis, 5]
# Esto solo es para quitar los valores vacíos (ceros) en las columnas.
X = np.reshape( X , len(X)).tolist()
y = np.reshape( y , len(y)).tolist()
X = np.array( [var if var > 20 else 20 for var in X] )[:, np.newaxis]
y = np.array( [val if val > 5 else 20 for val in y] )[:, np.newaxis]
# Separamos la información en training y test
X_train = X[:-20]
X_test = X[-20:]
# Separamos la salida (output) en training y test
y_train = y[:-20]
y_test = y[-20:]
# Creamos el objeto de linear regression
regr = linear_model.LinearRegression()
# Ahora entrenamos el modelo usando los conjuntos de training
regr.fit(X_train, y_train)
# Coeficientes
print 'Coefficients:', regr.coef_, regr.intercept_
# RSS
print "Residual sum of squares: %.2f" % np.mean((regr.predict(X_test) - y_test) ** 2)
# Ploteamos las salidas
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, regr.predict(X_test), color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.xlabel("Concentracion de glucosa")
plt.ylabel("Indice de masa corporal")
plt.show()
Salidas
Coefficients: [[ 0.06294299]]
Residual sum of squares: 46.59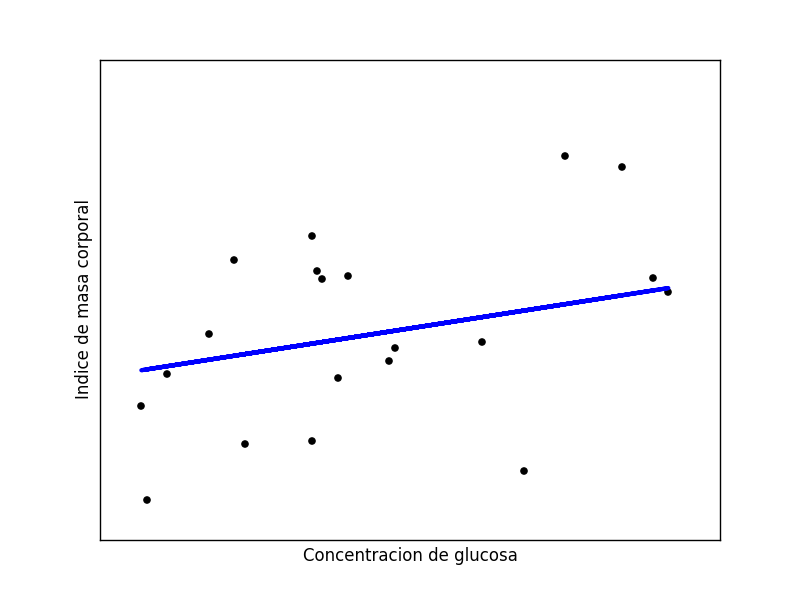 Plot 2: Dataset de diabetes remoto en formato CSV y modelo predictivo.
Plot 2: Dataset de diabetes remoto en formato CSV y modelo predictivo.
Y bueno Jordy ¿De dónde sacaste este código? Pues lo escribí yo mismo con algunas dificultades para quitar los valores nulos (ceros). Y sí, viendo algunos recursos en internet como el sagrado Stack Overflow. El dataset salió de aquí donde podemos encontrar más de estos para usarlos con fines de estudio.
No es difícil. Ya saben, es fácil hacerse senior en 6 meses.
Ejemplo 3: Procesando el dataset con SFrame. Predecir precio de una casa dado el área
# -*- coding: utf-8 -*-
from sklearn import linear_model
import sframe
import matplotlib.pyplot as plt
import numpy as np
data = sframe.SFrame("./kc_house_data.gl")
training, test = data.random_split(.8, seed=0) # Usar la misma semilla como buena práctica
X_train = training['sqft_living']
X_test = test['sqft_living']
y_train = training['price']
y_test = test['price']
# Creamos el objeto de linear regression
regr = linear_model.LinearRegression()
# Ahora entrenamos el modelo usando los conjuntos de training
regr.fit(X_train.to_numpy()[:,np.newaxis], y_train.to_numpy()[:,np.newaxis])
# Coeficientes
print 'Coefficients:', regr.coef_, regr.intercept_
# RSS
print "Residual sum of squares: %.2f" % ((regr.predict(X_test.to_numpy()[:,np.newaxis]) - y_test.to_numpy()[:,np.newaxis]) ** 2).mean()
# Ploteamos las salidas
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, regr.predict(X_test.to_numpy()[:,np.newaxis]), color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.xlabel("Medida en pies cuadrados")
plt.ylabel("Precio estimado")
plt.show()
Salidas
Coefficients: [[ 281.95883857]]
Residual sum of squares: 65122472510.56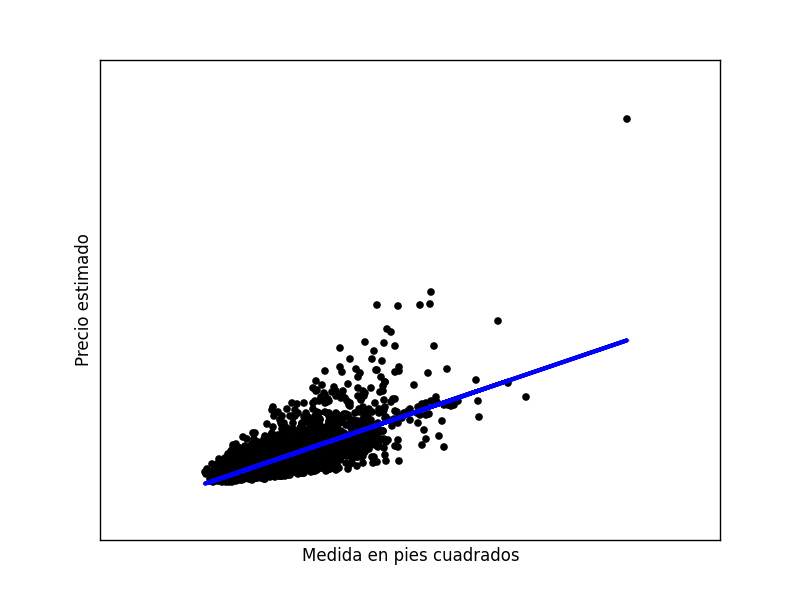 Plot 3: Dataset de casas usando SFrame.
Plot 3: Dataset de casas usando SFrame.
¿Por qué SFrame si es análogo? Bueno, he de decir que me agrada la manera en la que presenta los datos de modo más amigable cuando mandamos a imprimir uno de estos objetos. También los programadores de este, dicen que la información no es cargada en memoria, entonces tenemos una pequeña ventaja si trabajamos con equipos de menor memoria RAM. Quizá me quede corto con mi explicación pero en los siguientes links podrás ver otras de las maravillas que se pueden hacer con este tipo de datos (SFrame y SArray).
El dataset lo conseguí en este curso de Coursera: Machine Learning Regression.
Realmente espero que estos ejemplos les hayan ayudado. Ya les demostré cómo trabajar de diferentes formas con los datasets, lo siguiente serán los algoritmos.
¡Pero Jordy, ahora no explicaste la teoría y modelos matemáticos que hay detrás de esto! Cierto, necesitaré un poco de tiempo para escribir de modo legible el modelo matemático detrás de esto. Ya saben cuál será la próxima entrada.
Dudas / Comentarios
Si tienes alguna duda o comentario, escríbelo aquí o mandame un tweet a @JordyCRPetrucci y te ayudaré con gusto.